一次跌宕起伏的BUG修复——PVE节点出现Unknown状态故障
周日下午,老T准备在 PVE 装个 RouterOS 测试,结果发现无法创建虚拟机。具体表现是,在虚拟机创建页面,节点处提示 “Node epson seems to be offline” ,然后 PVE 面板上,节点显示灰色问号,提示状态为 “Unknown”。由此,开始了老T一段跌宕起伏的 Bug 修复过程。
PVE 存储设备配置冲突
遇到 Bug 后,老T第一时间怀疑是不是节点配置冲突。因为节点内的虚拟机本身在正常运行,除了节点上有灰色问号,在节点中还有两个存储设备也同样显示黑色问号。
这两个存储设备实际就是主机中的两个机械硬盘。此前,老T将这两个机械硬盘挂载后,直通给了 100 号虚拟机使用。
但考虑到虚拟机中无法读取硬盘温度,便分离了存储,改用 PCI-E 硬件直通,将 SATA 控制器直通到虚拟机。故此遗留两个过期的存储设备。
于是老T在 PVE 面板中直接删除了两个存储设备,然后刷新,看到问题依旧。
老T在想,是否是因为集群状态还没更新,于是重启并强制刷新集群状态,同时检查存储挂载情况。
1systemctl restart pve-cluster
2systemctl restart corosync
3pvesm status果然,存储状态有点问题。PVE 配置中保留了两个 HDD 的 LVM 存储定义,但实际物理磁盘已经直通给 100 号虚拟机不可见。
1root@epson:# pvesm status
2Command failed with status code 5.
3command '/sbin/vgscan --ignorelockingfailure --mknodes' failed: exit code 5
4Name Type Status Total Used Available %
5HDD1 lvm inactive 0 0 0 0.00%
6HDD2 lvm inactive 0 0 0 0.00%
7local dir active 98497780 13880408 79567824 14.09%
8local-lvm lvmthin active 832888832 126265946 706622885 15.16%于是老T 将无效存储配置进行清理,重新修复 PVE 集群状态。
1pvesm remove HDD1
2pvesm remove HDD2
3systemctl restart pve-storage.target
4pmxcfs -l # 重建集群配置文件
5pvecm updatecerts --force
6systemctl restart pve-cluster顺便再 reboot,想着问题应该解决了。
但重启后发现节点依然显示灰色问号。
集群配置文件错误
如果说,上边检查 PVE 存储配置时发现错误尚且简单,接下来检查 PVE 集群配置时,就开始逐渐入坑了。
1root@epson:~# pvecm status
2Error: Corosync config '/etc/pve/corosync.conf' does not exist - is this node part of a cluster? Linux epson 6.8.12-9-pve #1 SMP PREEMPT_DYNAMIC PMX 6.8.12-9 (2025-03-16T19:18Z) x86_64查看集群状态发现,corosync 配置文件丢失,一个稀奇古怪的 Bug。也不知道因何而起。
但在重建前,还有另一个小问题需要重视。
老T使劲查看了一遍 PVE 面板,发现除了节点显示灰色问号,还有另一个问题,就是节点上 CPU 和内存利用率这些基本信息也不显示,包括图表信息也都丢失,图标下方直接显示 1970 年 1 月 1 日。
系统时间
于是,老T开始怀疑是否是系统时间服务故障导致的这一系列问题。
1root@epson:# timedatectl
2Local time: Mon 2025-08--31 21:18:39 CST
3Universal time: Mon 2025-08--31 13:18:39 UTC
4RTC time: Mon 2025-08--31 13:18:39
5Time zone: Asia/Shanghai (CST, +0800)
6System clock synchronized: yes
7NTP service: active
8RTC in local TZ: no
9root@epson:# hwclock --show
102025-08--31 21:19:03.141107+08:00不过并未发现故障。系统时间都是正确的。
文件路径问题
没办法,只剩一条路,重建配置文件。
照旧,先检查一下 corosync 状态。
1root@epson:~# systemctl status corosync
2○ corosync.service - Corosync Cluster Engine
3 Loaded: loaded (/lib/systemd/system/corosync.service; enabled; preset: enabled)
4 Active: inactive (dead)
5 Condition: start condition failed at Mon 2025-09-01 21:13:46 CST; 6min ago
6 └─ ConditionPathExists=/etc/corosync/corosync.conf was not met
7 Docs: man:corosync
8 man:corosync.conf
9 man:corosync_overview
10
11Aug 31 21:13:46 epson systemd[1]: corosync.service - Corosync Cluster Engine was skipped because of an unmet condition check (ConditionPathExists=/etc/corosync/corosync.conf).
12root@epson:~#不检查不要紧,一检查状态又发现新问题。前边检查集群配置时,系统提示缺少 /etc/pve/corosync.conf ,但 corosync 状态却显示它在查找 /etc/corosync/corosync.conf,两个路径似乎不一致。
于是老T试图修复一下这个问题。结果并没有区别,corosync 依然提示无法查找到配置文件。
1oot@epson:# mount | grep /etc/pve
2/dev/fuse on /etc/pve type fuse (rw,nosuid,nodev,relatime,user_id=0,group_id=0,default_permissions,allow_other)
3root@epson:# mkdir -p /etc/corosync
4root@epson:# ln -s /etc/pve/corosync.conf /etc/corosync/corosync.conf重建集群配置
终于开始重建配置。
1root@epson:# systemctl stop pve-cluster pvedaemon pveproxy corosync # 停止服务
2root@epson:# rm -rf /etc/pve/* # 删除原配置
3root@epson:# rm -rf /var/lib/pve-cluster/* # 删除原配置
4root@epson:# mkdir /etc/pve # 重建目录
5root@epson:# mkdir /var/lib/pve-cluster # 重建目录
6# 写入配置
7root@epson:# cat > /etc/pve/corosync.conf <<EOF
8totem {
9version: 2
10cluster_name: epson
11transport: knet
12crypto_cipher: aes256
13crypto_hash: sha256
14}
15nodelist {
16node {
17name: epson
18nodeid: 1
19quorum_votes: 1
20ring0_addr: 192.168.1.8
21}
22}
23quorum {
24provider: corosync_votequorum
25expected_votes: 1
26}
27logging {
28to_syslog: yes
29}
30EOF
31
32root@epson:# chown root:www-data /etc/pve/corosync.conf
33root@epson:# chmod 640 /etc/pve/corosync.conf
34root@epson:# rm -f /etc/corosync/corosync.conf # 删除旧链接
35root@epson:# ln -s /etc/pve/corosync.conf /etc/corosync/corosync.conf
36root@epson:# systemctl daemon-reload
37root@epson:# systemctl start corosync
38Job for corosync.service failed because the control process exited with error code.
39See "systemctl status corosync.service" and "journalctl -xeu corosync.service" for details.一整套搞下来,过程都挺正常,但结果 corosync 还是崩了。查看日志发现,是缺少认证密钥文件 Could not open /etc/corosync/authkey: No such file or directory。
修复密钥文件
简单修复下密钥文件,并按照错误提示,将其链接到对应路径。
1root@epson:# corosync-keygen
2Corosync Cluster Engine Authentication key generator.
3Gathering 2048 bits for key from /dev/urandom.
4Writing corosync key to /etc/corosync/authkey.
5root@epson:# ln -s /etc/pve/authkey /etc/corosync/authkey重新检查 corosync 状态,发现这次终于没问题了。
1root@epson:~# systemctl status corosync
2● corosync.service - Corosync Cluster Engine
3Loaded: loaded (/lib/systemd/system/corosync.service; enabled; preset: enabled)
4Active: active (running) since Mon 2025-08-31 21:37:39 CST; 29s ago
5Docs: man:corosync
6man:corosync.conf
7man:corosync_overview
8Main PID: 18905 (corosync)
9Tasks: 9 (limit: 18833)
10Memory: 112.4M
11CPU: 204ms
12CGroup: /system.slice/corosync.service
13└─18905 /usr/sbin/corosync -f不过,corosync 虽然修复,但是最开始的 epson 节点上灰色问号问题依旧没能解决。也就是说,目前还是没能定位到实际问题所在。
重置配置
接下来开始进入深坑。
在开始重置集群配置前,照例先将 cluster 原本文件删除。结果,哦豁,PVE 彻底崩了。
1root@epson:# systemctl stop pve-cluster corosync pvedaemon pveproxy
2root@epson:# rm -rf /var/lib/pve-cluster/*
3root@epson:# pvecm updatecerts -f
4ipcc_send_rec[1] failed: Connection refused
5ipcc_send_rec[2] failed: Connection refused
6ipcc_send_rec[3] failed: Connection refused
7Unable to load access control list: Connection refused好在,此前在上一个环节中,还备份了文件,于是找到备份文件恢复过来。
想着起码不至于全崩吧,回到本次开局状态就行。
结果,问题依旧。查看日志,发现出了个奇奇怪怪的新问题,pmxcfs 无法打开数据库文件 ‘/var/lib/pve-cluster/config.db’。
1[database] crit: splite3_open_v2 failed: 14#010
2[main] crit: memdb_open failed - unable to open database '/var/lib/pve-cluster/config.db'抱着破罐子破摔的想法,要么就彻底来次重配吧。
1rm -rf /var/lib/pve-cluster/*
2rm -f /etc/corosync/corosync.conf
3rm -f /etc/pve/corosync.conf
4rm -f /var/lib/corosync/*
5
6apt-get install --reinstall --purge pve-cluster corosync于是,老T将 cluster 和 corosync 干脆一并删了,重新来过。
但,依旧失败。PVE 面板此时已经没法恢复。由于虚拟机还在运行,老T也没继续折腾。等第二天再弄。
二次修复集群配置
第二天早上,老T 早早的就起来,想着趁上班前早点修复这个。
不得不说,睡了一晚,人也清醒多了。
1# 检查备份现有文件
2ls -la /var/lib/pve-cluster/
3cp /var/lib/pve-cluster/config.db /root/config.db.bak.$(date +%Y%m%d)
4
5# 停止进程
6systemctl stop corosync pve-cluster pvedaemon pveproxy
7pkill -9 pmxcfs
8
9# 修复数据库
10sqlite3 /var/lib/pve-cluster/config.db ".dump" > /root/dump.sql
11sqlite3 /var/lib/pve-cluster/new_config.db < /root/dump.sql
12mv /var/lib/pve-cluster/new_config.db /var/lib/pve-cluster/config.db
13chown www-data:www-data /var/lib/pve-cluster/config.db
14chmod 0600 /var/lib/pve-cluster/config.db
15
16## 重启集群服务
17systemctl start pve-cluster不过,重启依然失败。查看日志,发现是 pmxcfs 无法挂载文件系统到 /etc/pve 。也是个稀奇古怪问题。
仔细检查 /etc/pve 路径发现,原来此前用的 rm -rf /etc/pve/* 命令,只是删除了目录中部分文件,对于以点(.)开头的隐藏文件并没有删除掉,导致目录实际不为空。
又重新来一遍,将 /etc/pve 目录移除,重新创建空目录。
然后将原来的两个虚拟机配置重新写入 /etc/pve/qemu-server/100.conf /etc/pve/qemu-server/101.conf。
总算是回到了起点。
即,PVE 中节点 epson 上显示灰色问号。折腾两趟,毫无起色。
远程把 PVE 干丢了
老T把这段过程,找 DeepSeek 复盘,看看中间到底哪里出了差错。结果它立马提醒,在恢复集群配置后,该立马更新网络配置。
也就是信了它的鬼,老T按照它提供方法,创建了网络配置,直接把远程 PVE 干离线了。
1# 创建临时网络配置
2cat << EOF > /etc/network/interfaces.tmp
3auto lo
4iface lo inet loopback
5
6auto eno1
7iface eno1 inet manual
8
9auto vmbr0
10iface vmbr0 inet static
11 address 192.168.1.238/24
12 gateway 192.168.1.1
13 bridge-ports eno1
14 bridge-stp off
15 bridge-fd 0
16EOF
17
18# 应用配置
19mv /etc/network/interfaces.tmp /etc/network/interfaces
20chmod 644 /etc/network/interfaces
21systemctl restart networking拯救 PVE 网络问题
一波未平一波又起,被 deepseek 这样一搞,心态又崩了。只能找 Gemini 来挽救下。
排查发现,PVE 网络本身并没啥太大问题,能够正常联网。
只是因为此前在写入两个虚拟机配置时,错写了磁盘空间格式,应该写成 64G 被老T写成 64 GiB,导致 PVE 无法解析磁盘。因而在网络配置重启后,无法连接到虚拟机。
但也就是在排查这个网络问题过程中,让老T看到一个新的问题。
在运行状态中显示,这个节点的名称叫 2606:4700:3037::6815:3752 ,而在corosync 配置中,这个节点名称叫 epson 。
按道理,当 corosync 服务启动时,它会读取配置文件中的 name: epson。然后,它需要将 epson 这个名字解析成一个 IP 地址,以便在网络上进行通信。如果在这个解析过程中失败了,corosync 可能会“自暴自弃”,直接使用IP地址作为自己的名字。
经详细检查发现,是因为老T之前曾修改过 PVE 的主机名,正常情况下,节点应该解析到 192.168.1.238,但添加了自定义域后,节点被解析到 Cloudflare 的 IP 。将 Hosts 顺序调整后,算是修复了这个 Bug。
1root@epson:~# getent hosts epson
22606:4700:3037::6815:3752 epson.fosu.cc
32606:4700:3031::ac43:91f8 epson.fosu.cc结局
我重新看了下 PVE 面板各项功能,在将硬件状态监控面板时长从“天”调整到“月”后,终于是发现大问题。
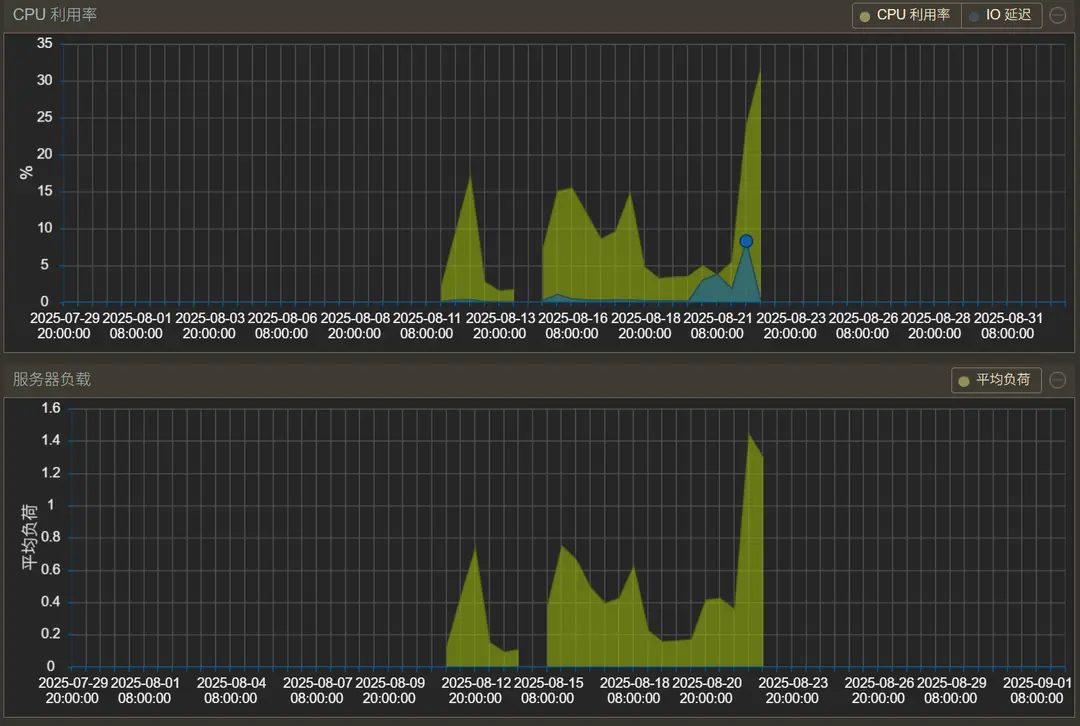
原来,这个PVE节点故障,已经存在 10 来天了。按照 8 月 21 日的时间节点,有可能是因为当时安装 PVEtools 的缘故。
由于当时为了解决飞牛系统中硬盘显示温度问题,过程中曾一度安装过 PVEtools 更改面板设置,添加了温度监控。
在想起这茬事后,立即开始验证。
1root@epson:~# dpkg --verify pve-manager # 验证文件改动情况
2missing c /etc/apt/sources.list.d/pve-enterprise.list
3??5?????? /usr/share/perl5/PVE/API2/Nodes.pm
4??5?????? /usr/share/pve-manager/js/pvemanagerlib.js毫无疑问,因为 PVEtools 的安装,导致 PVE 管理器后端 API 和核心 JS 库都被改动过。即便我印象中,安装 PVEtools 中相关组件后曾进行卸载,也不起作用。
于是重新安装 PVEmanager。这次终于是把 PVEtools 残留在面板上的温度显示给去掉了。
1apt-get update
2apt-get install --reinstall pve-manager接着继续排查,PVETools 安装后可能给 PVE 带来的负面影响。
经查看 PVE 各种组件状态,在排查到 PVE 状态守护组件时,发现它一直在疯狂报错。
1root@epson:~# systemctl status pvestatd # 验证PVE状态守护情况
2● pvestatd.service - PVE Status Daemon
3Loaded: loaded (/lib/systemd/system/pvestatd.service; enabled; preset: enabled)
4Active: active (running) since Tue 2025-09-01 19:07:31 CST; 5min ago
5Process: 1081 ExecStart=/usr/bin/pvestatd start (code=exited, status=0/SUCCESS)
6Main PID: 1116 (pvestatd)
7Tasks: 1 (limit: 18833)
8Memory: 156.2M
9CPU: 2.704s
10CGroup: /system.slice/pvestatd.service
11└─1116 pvestatd
12
13Sep 01 18:11:50 epson pvestatd[1116]: node status update error: Undefined subroutine &PVE::Network::ip_link_details called at /usr/share/perl5/PVE/Ser>
14Sep 01 18:12:00 epson pvestatd[1116]: node status update error: Undefined subroutine &PVE::Network::ip_link_details called at /usr/share/perl5/PVE/Ser>
15Sep 01 18:12:10 epson pvestatd[1116]: node status update error: Undefined subroutine &PVE::Network::ip_link_details最后,老T通过对 PVE 进行一次完整的组件升级,解决问题。
1apt update && apt full-upgrade问题回顾与总结
初始症状
- PVE 节点状态显示
unknown(灰色问号),无法创建虚拟机,节点性能图表丢失(显示 1970 年 1 月 1 日)。
- PVE 节点状态显示
弯路 1:误判存储配置冲突
- 怀疑直通硬盘遗留的无效存储配置(
HDD1/HDD2)导致问题,清理后重启但问题未解决。
- 怀疑直通硬盘遗留的无效存储配置(
弯路 2:错误重建集群配置
- 发现
corosync.conf丢失并尝试重建集群(包括修复路径、密钥文件),但节点状态异常依旧。
- 发现
弯路 3:被误导修改网络配置
- 依据错误建议重写网络配置,导致 PVE 失联,后修复 hosts 解析(节点名误解析到 Cloudflare IP)但核心故障仍在。
初步怀疑
- 结合时间线(故障始于 8 月 21 日)和操作历史,怀疑
pvetools脚本(曾用于添加温度监控)是根源。
- 结合时间线(故障始于 8 月 21 日)和操作历史,怀疑
关键证据 1
dpkg --verify pve-manager确认核心文件(Nodes.pm,pvemanagerlib.js)被pvetools修改。
第一次尝试
- 重装
pve-manager:恢复了被修改文件(温度监控消失),但节点状态异常仍未修复,表明问题更深层。
- 重装
决定性证据 2
- 检查
pvestatd日志发现致命错误:Undefined subroutine &PVE::Network::ip_link_details,明确指向库版本不匹配。
- 检查
根本原因
- PVE 组件版本冲突:新版本
pve-manager调用了旧版 Perl 库(如libpve-common-perl)中不存在的函数。
- PVE 组件版本冲突:新版本
最终解决方案
- 执行完整系统升级:
apt update && apt full-upgrade,同步所有 PVE 组件至兼容版本,彻底解决问题。
- 执行完整系统升级:
#proxmox ve #节点故障 #集群配置 #存储冲突 #corosync