手搓RSSHub路由失败

前几天在NameCheap白嫖 .news 域名,注册了个 hy2.news,想着也没啥用就搭建一下个人动态页面。既然是动态的,那就得把 Wordpress 请出来,然后用 RSS 插件实现。页面地址:Hyruo News
页面是搭好了,RSS 来源成了问题,于是摸索着先从最近几个月混得比较活跃的 Nodeseek 论坛搞起。结果搞半天还是失败了。
RSSHub 手搓路由方法
RSSHub 官网的开发路由教程比较跳跃,主要过程如下。
前期工作
- 克隆 RSSHub 仓库 (电脑慢的话要半个小时以上)
git clone https://github.com/DIYgod/RSSHub.git - 安装最新版本 Node.js (版本要大于 22)Node.js 官网地址
- 安装依赖项
pnpm i - 运行
pnpm run dev
开发路由
开发路由就比较简单,打开 RSSHub\lib\routes 目录,在下边新建一个文件夹,比如 nodeseek,然后在该文件夹中添加两个文件 namespace.ts custom.ts 就完事。
- namespace.ts 文件
这个文件照着官方教程就行,不然就随便在 lib\routes 目录下边复制别人的改改。示例如下:
import type { Namespace } from '@/types';
export const namespace: Namespace = {
name: 'nodeseek',
url: 'nodeseek.com',
lang: 'zh-CN',
};- custom.ts 文件
这是开发路由的主文件,文件名可以按照目标网站结构来命名,看看其他文件夹就懂,难度主要是在具体内容上。示例如下:
import { Route } from '@/types';
import { load } from 'cheerio';
import { parseDate } from '@/utils/parse-date';
import logger from '@/utils/logger';
import puppeteer from '@/utils/puppeteer';
import cache from '@/utils/cache';
export const route: Route = {
path: '/user/:userId',
categories: ['bbs'],
example: '/nodeseek/user/1',
parameters: { userId: '用户 ID,例如 1' },
features: {
requireConfig: false,
requirePuppeteer: true, // 启用 Puppeteer
antiCrawler: true, // 启用反爬虫
supportBT: false,
supportPodcast: false,
supportScihub: false,
},
radar: [
{
source: ['nodeseek.com/space/:userId'],
target: '/user/:userId',
},
],
name: 'NodeSeek 用户话题',
maintainers: ['你的名字'],
handler: async (ctx) => {
const userId = ctx.req.param('userId');
const baseUrl = 'https://www.nodeseek.com';
const userUrl = `${baseUrl}/space/${userId}#/discussions`;
// 导入 puppeteer 工具类并初始化浏览器实例
const browser = await puppeteer();
// 打开一个新标签页
const page = await browser.newPage();
// 设置请求头
await page.setExtraHTTPHeaders({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36',
Referer: baseUrl,
Accept: 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
});
// 访问目标链接
logger.http(`Requesting ${userUrl}`);
await page.goto(userUrl, {
waitUntil: 'networkidle2', // 等待页面完全加载
});
// 模拟滚动页面(如果需要)
await page.evaluate(() => {
window.scrollBy(0, window.innerHeight);
});
// 等待帖子列表加载
await page.waitForSelector('a[href^="/post-"]', { timeout: 7000 });
// 获取页面的 HTML 内容
const response = await page.content();
const $ = load(response);
// 提取帖子列表
let items = $('a[href^="/post-"]')
.toArray()
.map((item) => {
const $item = $(item);
const title = $item.find('span').text().trim();
const link = `${baseUrl}${$item.attr('href')}`;
return {
title,
link,
};
});
// 排除页脚的两个固定链接
const excludedLinks = ['/post-6797-1', '/post-6800-1'];
items = items.filter((item) => !excludedLinks.includes(new URL(item.link).pathname));
// 最多提取 15 个帖子
items = items.slice(0, 15);
// 打印提取的帖子列表
console.log('提取的帖子列表:', items); // 调试信息
// 如果帖子列表为空,可能是页面未加载动态内容
if (items.length === 0) {
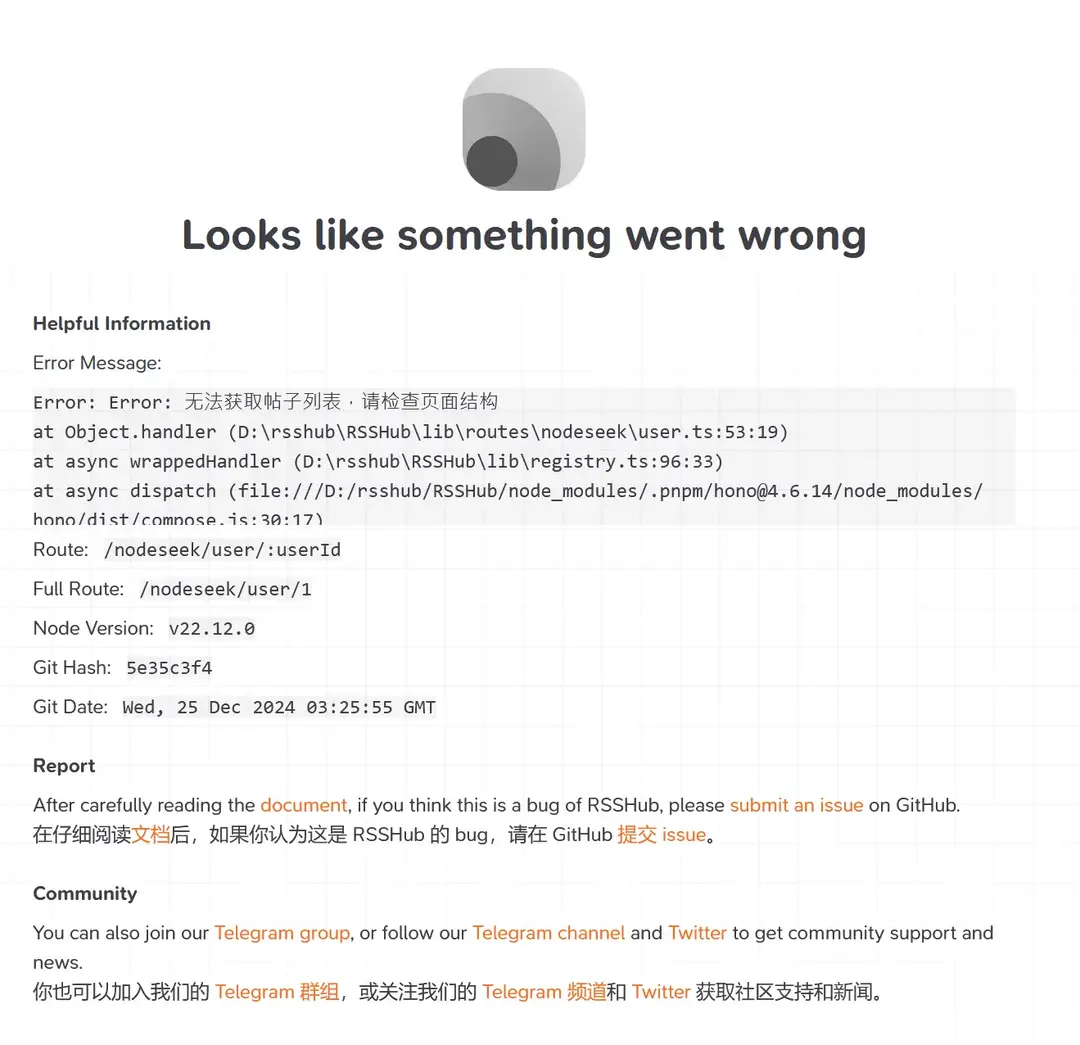
throw new Error('无法获取帖子列表,请检查页面结构');
}
// 获取每个帖子的内容
items = await Promise.all(
items.map((item) =>
cache.tryGet(item.link, async () => {
// 打开一个新标签页
const postPage = await browser.newPage();
// 设置请求头
await postPage.setExtraHTTPHeaders({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36',
Referer: baseUrl,
});
// 访问帖子链接
logger.http(`Requesting ${item.link}`);
await postPage.goto(item.link, {
waitUntil: 'networkidle2', // 等待页面完全加载
});
// 获取帖子内容
const postHtml = await postPage.content();
const $post = load(postHtml);
item.description = $post('article.post-content').html();
item.pubDate = parseDate($post('time').attr('datetime'));
// 关闭帖子页面
await postPage.close();
return item;
})
)
);
// 关闭浏览器实例
await browser.close();
// 返回 RSS 数据
return {
title: `NodeSeek 用户 ${userId} 的话题`,
link: userUrl,
item: items,
};
},
};本次主要问题总结
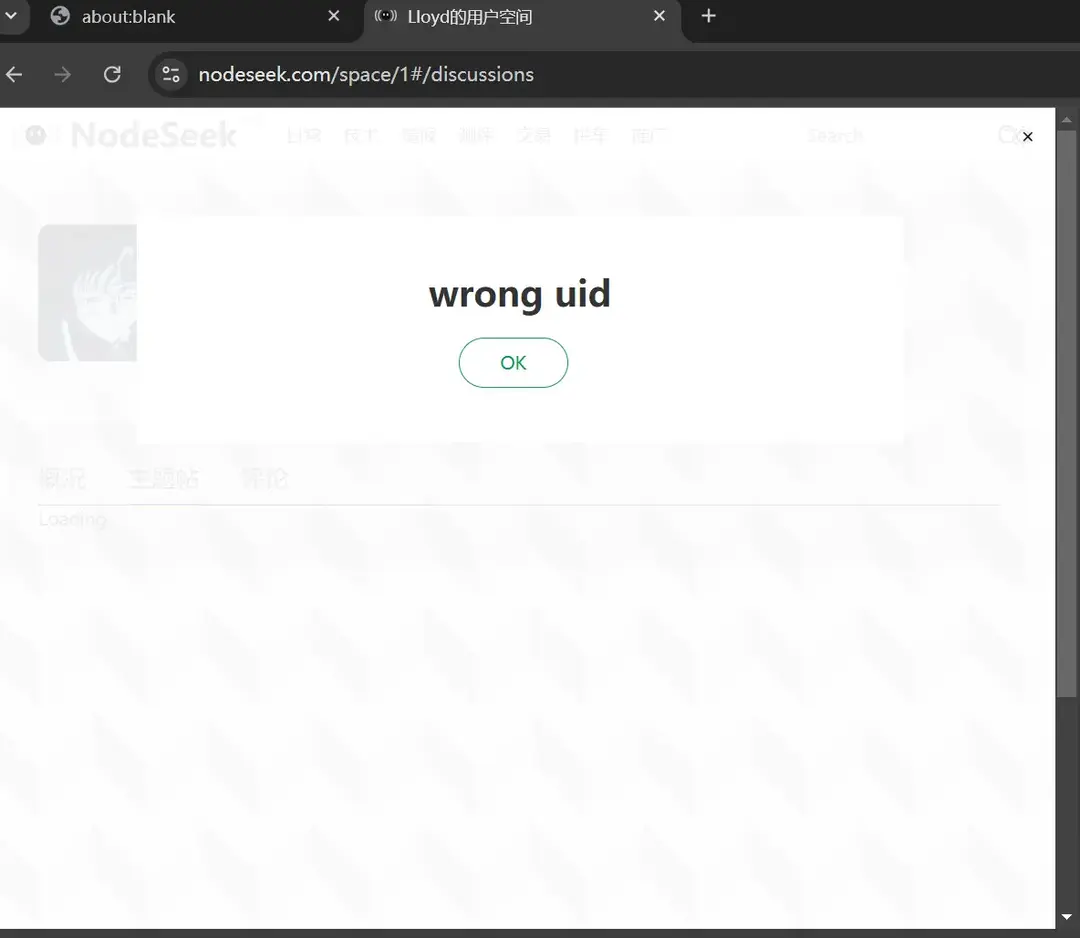
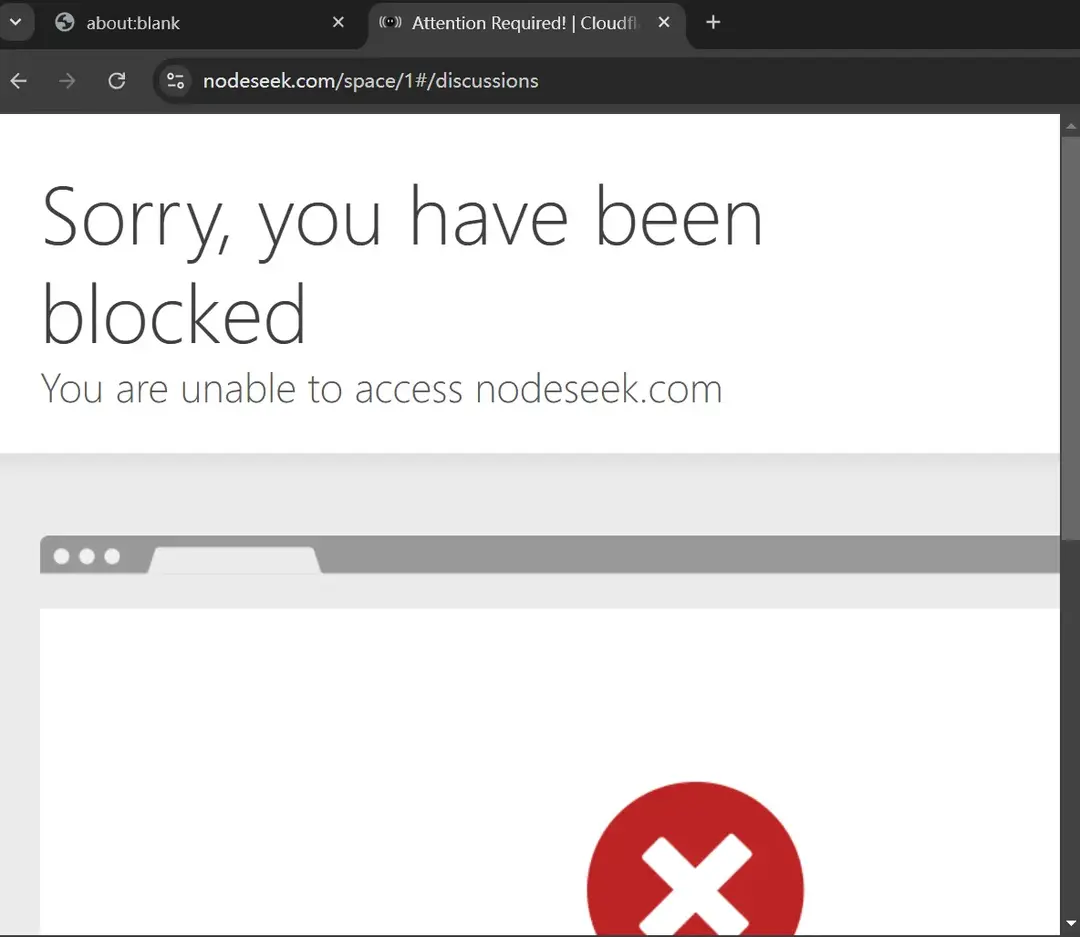
简单说本次手搓 nodeseek 路由失败原因,主要就是没能突破 nodeseek 的反爬和 cloudflare 盾限制。
RSSHub 可以使用的极限方法就是利用 Puppeteer 来模拟浏览器行为反爬,问题是机器模拟行为很容易在攻防中被 cf 这种平台识别出来。
我在本地测试时,大概有个 50% 的成功率,这还是在本地更新最新版本 Puppeteer 的情况下,如果用 RSSHub 官方依赖中的 Puppeteer 版本,成功率不足 10%。考虑提交至 RSSHub 还要经过双重审核,这成功率没法看了。
最终只能先忍痛放弃先。
屋漏偏逢连夜雨
今早一起床发现天塌了,6 个 *.US.KG 免费域名因上级域名被停止解析而崩盘。
今天中午发现天又塌了一遍。好不容易弄好的 .news 域名又被官方暂停了。邮件发过来让我好好解释下为啥在注册过程中个人信息出现变更,然后强行将 NS 解析到鬼都不认识的 IP 上。
好吧,这个是我自己问题。一开始注册时直接套浏览器自动填单程序,一不小心全给填了真实信息。然后想着改回来,一改就出异常了。
PS:下午 *.us.kg 又恢复正常。但感觉不会再爱它了。
#rsshub #路由开发 #反爬虫 #nodeseek #puppeteer