A Rollercoaster Bug Fix Journey – PVE Node Shows 'Unknown' Status Failure
On a Sunday afternoon, Lawtee planned to install RouterOS on PVE for testing, only to find that creating a virtual machine was impossible. The specific issue was that on the VM creation page, the node field displayed “Node epson seems to be offline,” and on the PVE panel, the node showed a gray question mark with a status of “Unknown.” Thus began Old T’s rollercoaster journey of bug fixing.
PVE Storage Device Configuration Conflict
Upon encountering the bug, Lawtee first suspected a node configuration conflict. Although the VMs within the node were running normally, aside from the gray question mark on the node, two storage devices also displayed black question marks.
These two storage devices were actually mechanical hard drives in the host. Previously, Lawtee had mounted these drives and passed them through to VM 100 for use.
However, since the VM couldn’t read the hard drive temperatures, the storage was detached, and PCI-E hardware passthrough was used instead to pass the SATA controller directly to the VM. This left two outdated storage devices behind.
So, Lawtee directly deleted the two storage devices from the PVE panel and refreshed, but the issue persisted.
Wondering if the cluster state hadn’t updated yet, Lawtee restarted and forcibly refreshed the cluster state while checking the storage mount status.
1systemctl restart pve-cluster
2systemctl restart corosync
3pvesm statusSure enough, there was an issue with the storage status. The PVE configuration retained the LVM storage definitions for the two HDDs, but the physical disks were no longer visible as they had been passed through to VM 100.
1root@epson:# pvesm status
2Command failed with status code 5.
3command '/sbin/vgscan --ignorelockingfailure --mknodes' failed: exit code 5
4Name Type Status Total Used Available %
5HDD1 lvm inactive 0 0 0 0.00%
6HDD2 lvm inactive 0 0 0 0.00%
7local dir active 98497780 13880408 79567824 14.09%
8local-lvm lvmthin active 832888832 126265946 706622885 15.16%Lawtee then cleaned up the invalid storage configurations and repaired the PVE cluster state.
1pvesm remove HDD1
2pvesm remove HDD2
3systemctl restart pve-storage.target
4pmxcfs -l # Rebuild cluster configuration files
5pvecm updatecerts --force
6systemctl restart pve-clusterA reboot followed, hoping the issue would be resolved.
But after restarting, the node still showed a gray question mark.
Cluster Configuration File Error
If discovering the PVE storage configuration error earlier was straightforward, checking the PVE cluster configuration next led Lawtee into a deeper rabbit hole.
1root@epson:~# pvecm status
2Error: Corosync config '/etc/pve/corosync.conf' does not exist - is this node part of a cluster? Linux epson 6.8.12-9-pve #1 SMP PREEMPT_DYNAMIC PMX 6.8.12-9 (2025-03-16T19:18Z) x86_64Checking the cluster status revealed that the corosync configuration file was missing—a bizarre bug with no clear cause.
Before rebuilding, another minor issue needed attention.
Lawtee scrutinized the PVE panel again and noticed that, besides the gray question mark on the node, basic information like CPU and memory usage wasn’t displayed, and the charts were missing, showing January 1, 1970, below the icons.
System Time
This led Lawtee to suspect that a system time service failure might be causing these issues.
1root@epson:# timedatectl
2Local time: Mon 2025-08--31 21:18:39 CST
3Universal time: Mon 2025-08--31 13:18:39 UTC
4RTC time: Mon 2025-08--31 13:18:39
5Time zone: Asia/Shanghai (CST, +0800)
6System clock synchronized: yes
7NTP service: active
8RTC in local TZ: no
9root@epson:# hwclock --show
102025-08--31 21:19:03.141107+08:00However, no faults were found; the system time was correct.
File Path Issue
With no other options left, the only path was to rebuild the configuration file.
As usual, Lawtee first checked the corosync status.
1root@epson:~# systemctl status corosync
2○ corosync.service - Corosync Cluster Engine
3 Loaded: loaded (/lib/systemd/system/corosync.service; enabled; preset: enabled)
4 Active: inactive (dead)
5 Condition: start condition failed at Mon 2025-09-01 21:13:46 CST; 6min ago
6 └─ ConditionPathExists=/etc/corosync/corosync.conf was not met
7 Docs: man:corosync
8 man:corosync.conf
9 man:corosync_overview
10
11Aug 31 21:13:46 epson systemd[1]: corosync.service - Corosync Cluster Engine was skipped because of an unmet condition check (ConditionPathExists=/etc/corosync/corosync.conf).
12root@epson:~#This check revealed a new problem. Earlier, the cluster check indicated a missing /etc/pve/corosync.conf, but the corosync status showed it was looking for /etc/corosync/corosync.conf—the paths seemed inconsistent.
Lawtee attempted to fix this issue, but it made no difference; corosync still couldn’t find the configuration file.
1oot@epson:# mount | grep /etc/pve
2/dev/fuse on /etc/pve type fuse (rw,nosuid,nodev,relatime,user_id=0,group_id=0,default_permissions,allow_other)
3root@epson:# mkdir -p /etc/corosync
4root@epson:# ln -s /etc/pve/corosync.conf /etc/corosync/corosync.confRebuilding Cluster Configuration
Finally, the configuration rebuilding began.
1root@epson:# systemctl stop pve-cluster pvedaemon pveproxy corosync # Stop services
2root@epson:# rm -rf /etc/pve/* # Delete original configuration
3root@epson:# rm -rf /var/lib/pve-cluster/* # Delete original configuration
4root@epson:# mkdir /etc/pve # Recreate directory
5root@epson:# mkdir /var/lib/pve-cluster # Recreate directory
6# Write configuration
7root@epson:# cat > /etc/pve/corosync.conf <<EOF
8totem {
9version: 2
10cluster_name: epson
11transport: knet
12crypto_cipher: aes256
13crypto_hash: sha256
14}
15nodelist {
16node {
17name: epson
18nodeid: 1
19quorum_votes: 1
20ring0_addr: 192.168.1.8
21}
22}
23quorum {
24provider: corosync_votequorum
25expected_votes: 1
26}
27logging {
28to_syslog: yes
29}
30EOF
31
32root@epson:# chown root:www-data /etc/pve/corosync.conf
33root@epson:# chmod 640 /etc/pve/corosync.conf
34root@epson:# rm -f /etc/corosync/corosync.conf # Remove old link
35root@epson:# ln -s /etc/pve/corosync.conf /etc/corosync/corosync.conf
36root@epson:# systemctl daemon-reload
37root@epson:# systemctl start corosync
38Job for corosync.service failed because the control process exited with error code.
39See "systemctl status corosync.service" and "journalctl -xeu corosync.service" for details.Everything seemed normal during the process, but corosync still crashed. Checking the logs revealed a missing authentication key file: Could not open /etc/corosync/authkey: No such file or directory.
Fixing the Key File
Lawtee quickly generated the key file and linked it to the correct path as per the error.
1root@epson:# corosync-keygen
2Corosync Cluster Engine Authentication key generator.
3Gathering 2048 bits for key from /dev/urandom.
4Writing corosync key to /etc/corosync/authkey.
5root@epson:# ln -s /etc/pve/authkey /etc/corosync/authkeyRechecking the corosync status showed it was finally working.
1root@epson:~# systemctl status corosync
2● corosync.service - Corosync Cluster Engine
3Loaded: loaded (/lib/systemd/system/corosync.service; enabled; preset: enabled)
4Active: active (running) since Mon 2025-08-31 21:37:39 CST; 29s ago
5Docs: man:corosync
6man:corosync.conf
7man:corosync_overview
8Main PID: 18905 (corosync)
9Tasks: 9 (limit: 18833)
10Memory: 112.4M
11CPU: 204ms
12CGroup: /system.slice/corosync.service
13└─18905 /usr/sbin/corosync -fHowever, even though corosync was fixed, the original issue of the gray question mark on the epson node remained unresolved. The root cause was still elusive.
Resetting Configuration
This marked the beginning of the deep dive.
Before resetting the cluster configuration, Lawtee deleted the original cluster files as usual. But, oh no—PVE completely crashed.
1root@epson:# systemctl stop pve-cluster corosync pvedaemon pveproxy
2root@epson:# rm -rf /var/lib/pve-cluster/*
3root@epson:# pvecm updatecerts -f
4ipcc_send_rec[1] failed: Connection refused
5ipcc_send_rec[2] failed: Connection refused
6ipcc_send_rec[3] failed: Connection refused
7Unable to load access control list: Connection refusedFortunately, Lawtee had backed up files earlier and restored them from the backup.
Hoping to at least return to the initial state without a complete crash, Lawtee proceeded.
Yet, the problem persisted. Checking the logs revealed a strange new issue: pmxcfs couldn’t open the database file ‘/var/lib/pve-cluster/’.config.db’.
1[database] crit: splite3_open_v2 failed: 14#010
2[main] crit: memdb_open failed - unable to open database '/var/lib/pve-cluster/config.db'With a “nothing left to lose” mindset, Lawtee decided to go for a complete reconfiguration.
1rm -rf /var/lib/pve-cluster/*
2rm -f /etc/corosync/corosync.conf
3rm -f /etc/pve/corosync.conf
4rm -f /var/lib/corosync/*
5
6apt-get install --reinstall --purge pve-cluster corosyncSo, Lawtee completely removed the cluster and corosync, intending to start fresh.
But it still failed. The PVE web interface was now unrecoverable. Since the virtual machines were still running, Lawtee didn’t push further and decided to tackle it again the next day.
Second Attempt at Cluster Repair
The next morning, Lawtee got up early, hoping to fix this before work.
Admittedly, a good night’s sleep brought much clearer thinking.
1# Check and backup existing files
2ls -la /var/lib/pve-cluster/
3cp /var/lib/pve-cluster/config.db /root/config.db.bak.$(date +%Y%m%d)
4
5# Stop processes
6systemctl stop corosync pve-cluster pvedaemon pveproxy
7pkill -9 pmxcfs
8
9# Repair the database
10sqlite3 /var/lib/pve-cluster/config.db ".dump" > /root/dump.sql
11sqlite3 /var/lib/pve-cluster/new_config.db < /root/dump.sql
12mv /var/lib/pve-cluster/new_config.db /var/lib/pve-cluster/config.db
13chown www-data:www-data /var/lib/pve-cluster/config.db
14chmod 0600 /var/lib/pve-cluster/config.db
15
16## Restart cluster services
17systemctl start pve-clusterHowever, the restart still failed. Checking the logs revealed that pmxcfs couldn’t mount the filesystem to /etc/pve. Another peculiar issue.
A closer look at the /etc/pve path showed that the previous rm -rf /etc/pve/* command only deleted some files in the directory, leaving hidden files (those starting with a dot .) untouched, meaning the directory wasn’t actually empty.
So, he went through the process again, removed the /etc/pve directory entirely, and recreated an empty one.
Then, he rewrote the original two VM configurations into /etc/pve/qemu-server/100.conf and /etc/pve/qemu-server/101.conf.
Finally, he was back to square one.
That is, the node ’epson’ in PVE showed a grey question mark. Two rounds of effort, no progress.
Remotely Breaking PVE Connectivity
Lawtee reviewed this process with DeepSeek to figure out where things went wrong. It immediately suggested updating the network configuration right after restoring the cluster config.
Trusting its advice (perhaps foolishly), Lawtee followed its method to create a network configuration, which promptly took the remote PVE instance offline.
1# Create temporary network configuration
2cat << EOF > /etc/network/interfaces.tmp
3auto lo
4iface lo inet loopback
5
6auto eno1
7iface eno1 inet manual
8
9auto vmbr0
10iface vmbr0 inet static
11 address 192.168.1.238/24
12 gateway 192.168.1.1
13 bridge-ports eno1
14 bridge-stp off
15 bridge-fd 0
16EOF
17
18# Apply configuration
19mv /etc/network/interfaces.tmp /etc/network/interfaces
20chmod 644 /etc/network/interfaces
21systemctl restart networkingRescuing the PVE Network
Just as one wave subsided, another arose. This mishap with deepseek was frustrating. Lawtee turned to Gemini for help.
Investigation revealed that the PVE network itself wasn’t the main issue; it could connect to the network normally.
The problem stemmed from an earlier mistake when writing the two VM configurations: the disk space format was incorrectly written as ‘64 GiB’ instead of ‘64G’, causing PVE to fail parsing the disk settings. Consequently, after the network restart, it couldn’t connect to the VMs properly.
However, during this network troubleshooting, Lawtee noticed a new issue.
The running status showed the node name as 2606:4700:3037::6815:3752, while in the corosync configuration, the node name was epson.
In theory, when the corosync service starts, it should read the name ’epson’ from the config file. Then, it needs to resolve ’epson’ to an IP address for network communication. If this resolution fails, corosync might “give up” and use the IP address directly as its name.
A detailed check revealed that Lawtee had previously modified the PVE hostname. Normally, the node should resolve to 192.168.1.238, but after adding a custom domain, the node was resolving to a Cloudflare IP address. Adjusting the Hosts file order finally fixed this bug.
1root@epson:~# getent hosts epson
22606:4700:3037::6815:3752 epson.fosu.cc
32606:4700:3031::ac43:91f8 epson.fosu.ccThe Resolution
I took another look at the various functions in the PVE panel. After changing the hardware status monitoring panel’s timeframe from “Day” to “Month”, I finally spotted the major issue.
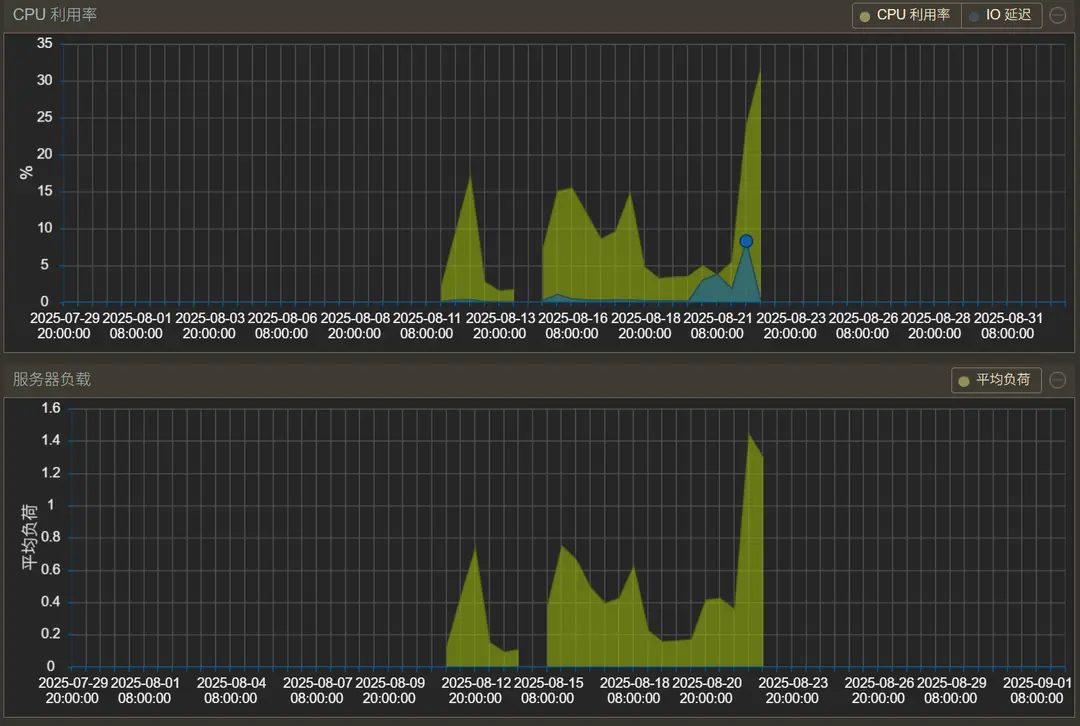
It turned out this PVE node failure had been present for about 10 days. Pinpointing the timeline around August 21st, it was likely related to the installation of PVEtools at that time.
Back then, to solve the hard drive temperature display issue in the Feiniu system, I had installed PVEtools to modify panel settings and add temperature monitoring.
Remembering this, I immediately started verifying.
1root@epson:~# dpkg --verify pve-manager # Verify file changes
2missing c /etc/apt/sources.list.d/pve-enterprise.list
3??5?????? /usr/share/perl5/PVE/API2/Nodes.pm
4??5?????? /usr/share/pve-manager/js/pvemanagerlib.jsUnsurprisingly, the installation of PVEtools had modified the PVE manager’s backend API and core JS library. Even though I recalled uninstalling the relevant PVEtools components afterward, it didn’t revert the changes.
So, I reinstalled PVEmanager. This finally removed the temperature display that PVEtools had left on the panel.
1apt-get update
2apt-get install --reinstall pve-managerNext, I continued investigating the potential negative impacts PVEtools might have had on PVE.
While checking the status of various PVE components, I found that the PVE status daemon was constantly throwing errors.
1root@epson:~# systemctl status pvestatd # Check PVE status daemon
2● pvestatd.service - PVE Status Daemon
3Loaded: loaded (/lib/systemd/system/pvestatd.service; enabled; preset: enabled)
4Active: active (running) since Tue 2025-09-01 19:07:31 CST; 5min ago
5Process: 1081 ExecStart=/usr/bin/pvestatd start (code=exited, status=0/SUCCESS)
6Main PID: 1116 (pvestatd)
7Tasks: 1 (limit: 18833)
8Memory: 156.2M
9CPU: 2.704s
10CGroup: /system.slice/pvestatd.service
11└─1116 pvestatd
12
13Sep 01 18:11:50 epson pvestatd[1116]: node status update error: Undefined subroutine &PVE::Network::ip_link_details called at /usr/share/perl5/PVE/Ser>
14Sep 01 18:12:00 epson pvestatd[1116]: node status update error: Undefined subroutine &PVE::Network::ip_link_details called at /usr/share/perl5/PVE/Ser>
15Sep 01 18:12:10 epson pvestatd[1116]: node status update error: Undefined subroutine &PVE::Network::ip_link_detailsFinally, Lawtee resolved the issue by performing a complete upgrade of the PVE components.
1apt update && apt full-upgradeProblem Review and Summary
Initial Symptoms
- PVE node status showed
unknown(grey question mark), inability to create VMs, missing node performance graphs (showing January 1, 1970).
- PVE node status showed
Detour 1: Misjudged Storage Configuration Conflict
- Suspected invalid storage configurations (
HDD1/HDD2) from passed-through HDDs caused the issue. Cleared them and rebooted, but the problem persisted.
- Suspected invalid storage configurations (
Detour 2: Mistakenly Rebuilt Cluster Configuration
- Discovered
corosync.confwas missing and attempted to rebuild the cluster (including fixing paths, key files), but the node status anomaly remained.
- Discovered
Detour 3: Misled into Modifying Network Configuration
- Followed erroneous advice to rewrite network configuration, causing PVE to lose connectivity. Later fixed hosts resolution (node name incorrectly resolved to Cloudflare IP), but the core fault persisted.
Initial Suspicion
- Combined timeline (fault started around August 21st) and operation history, suspected the
pvetoolsscript (used to add temperature monitoring) was the root cause.
- Combined timeline (fault started around August 21st) and operation history, suspected the
Key Evidence 1
dpkg --verify pve-managerconfirmed core files (Nodes.pm,pvemanagerlib.js) were modified bypvetools.
First Attempt
- Reinstalled
pve-manager: restored the modified files (temperature monitoring disappeared), but the node status anomaly still wasn’t fixed, indicating a deeper issue.
- Reinstalled
Decisive Evidence 2
- Checked
pvestatdlogs and found the critical error:Undefined subroutine &PVE::Network::ip_link_details, clearly pointing to library version mismatch.
- Checked
Root Cause
- PVE Component Version Conflict: The newer version of
pve-managerwas calling a function that didn’t exist in the older Perl libraries (likelibpve-common-perl).
- PVE Component Version Conflict: The newer version of
Final Solution
- Executed a full system upgrade:
apt update && apt full-upgrade, synchronizing all PVE components to compatible versions, completely resolving the issue.
- Executed a full system upgrade: